Whisper Showdown
C++ vs. Native: Speed, cost, YouTube transcriptions, visualizations, and benchmarks

Introduction
OpenAI’s Whisper has come far since 2022. It once needed costly GPUs, but intrepid developers made it work on regular CPUs. They even got it running on Android phones!
Transcriptions matter more than ever for large language model applications like ChatGPT and GPT-4. I wanted to create an app to “chat” with YouTube channels (for a future article), but to do this, I need to transcribe entire channels fast and cheap. I could try YouTube captions, but those can be unreliable, and from an engineering point of view, I don’t want to lock-in to the YouTube platform. This is a fun challenge!
Whisper is a powerful automatic speech recognition (ASR) model that has SOTA performance and is released under the MIT license. I thought it would be great if I could prototype code on my Mac and execute larger jobs on more powerful systems… but what are the trade-offs? There are several models ranging in size that have different memory requirements — surely, the CPU-based implementations have limitations? I was curious about how the various solutions scaled.
I have an M1 Pro laptop, an M2 Pro mini, and a PC with an older Intel 9900k and Nvidia RTX 2080 Ti. I also have a runpod.io account and an Eve smart plug that can do rudimentary power consumption measurements. I checked the speed and cost for each setup.
I will share benchmarks and test results. Plus, code to transcribe YouTube videos using whisper.cpp (CPU) and openai-whisper (GPU), as well as code to visualize the benchmark results with matplotlib.
Want to try it yourself? Use my code to run your own tests.
In this article, you will find the following:
- Whisper benchmarks and results
- Python/PyTube code to transcribe YouTube videos (CPU native and GPU /PyTorch)
- Python/Matplotlib code to see results easily with some price/performance logic
This isn’t meant to provide definitive answers but instead, provide a framework for thinking about the problem.
What is Whisper?
Whisper is a general-purpose speech recognition system developed by OpenAI. Trained on 680,000 hours of multilingual and multitasking supervised data collected from the web. This leads to improved robustness to accents, background noise, and technical language. High accuracy and ease of use can allow developers to add voice interfaces to a much wider set of applications. Whisper can be used for speech-to-text transcription, multilingual speech recognition, language identification/translation, and voice-controlled virtual assistants.
GitHub — openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
whisper.cpp
Whisper.cpp is a high-performance inference of OpenAI’s Whisper automatic speech recognition (ASR) model written in C/C++; it has low memory usage and runs on CPUs like Apple Silicon (M1, M2, etc.)]
Weighting models
Finding the right balance between speed and cost in machine learning is tricky. But here are some tips:
- Think about the project’s needs. Is low cost important? Focus on cost. Do you need fast results? Pick speed.
- Check the model’s quality. A fast but wrong model isn’t good. A cheap but bad model isn’t worth it.
- Plan for growth. For big projects, balance speed, cost, and quality.
- Know your limits. Look at your money, tools, and time. Pick what matters most.
- How often will you use it? If used a lot, speed and cost are important.
Try different mixes. Find what works best for your project.

Test Methodology
I had five different machines/six environments running Python 3.10.11. The Windows machine was running its code using WSL via Ubuntu, so there could be some overhead there (supposedly negligible):
- CPU #1: Apple M1 Pro (MacBook 16gb, Nov 2020) — 38 watts
- CPU #2: Apple M2 Pro (Mini 32gb, Jan 2023) — 50 watts
- CPU #3: Windows 11 via Ubuntu 22 (32gb, Oct 2018) — 162 watts
- GPU #1: RTX 2080 Ti (12gb VRAM, Sep 2018) — 297 watts
- GPU #2: RTX 4090 (24gb, Oct 2022) —no energy, but rental cost 0.64 $/hr
- GPU #3: A100 (80GB 16 vCPU 62 GB RAM, Jun 2020) — no energy, but rental cost $1.89/hr
I transcribed a popular video by Sabine Hossenfelder (Great YouTuber. Check out their videos) (duration: 00:16:06.08). I thought this a good example as it’s regular length, one speaker (note: no diarization with Whisper), and Sabine has an accent.
Each of the tests was run on their respective CPU or GPU architectures. The transcribe method is wrapped in a simple timer.
YouTube to Whisper — C++ — GitHub Repository
Whisper Transcriber’s (using whisper.cpp: CPU with python-bindings by aarnphm) elapsed execution time:
YouTube to Whisper — GPU — GitHub Repository
Whisper Transcriber’s (openai-whisper: CUDA/GPU) elapsed execution time:
Results
OK, let's take a look at the results. The following shows the CSV of the average timings.
Note the transcription output is the last column. I took the average of three executions for each model on each system. The transcription results are interesting too, and they surprisingly perform well for the tiny model. There are subtle differences in the transcriptions between the respective models. Tiny models may be good enough for most well-recorded English language transcriptions.
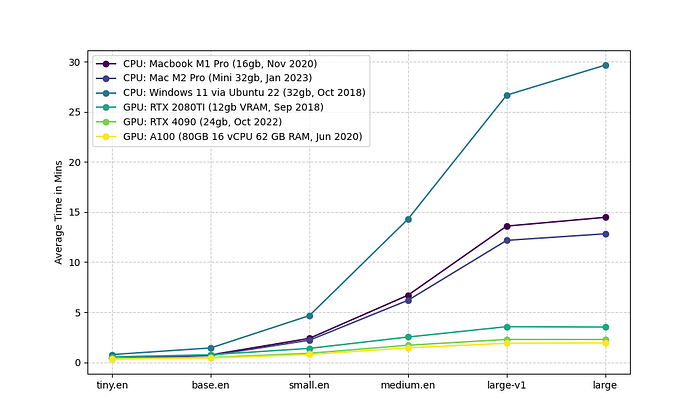
The first matplotlib visualization shows the average time in minutes for each of the machines, the chart doesn’t visualize the smaller differences very well, but things become more noticeable as you move into the medium and large models. The older PC CPU is by far the slowest (and that’s using 4x the power of the Apple Silicon machines), but the rest can finish the 16-minute video transcription in under 15 mins.
The M1 and M2 have very similar performance despite the M2 having double the memory. They slow down significantly when you get to medium.en, but perform fantastically with the smaller models. Another interesting thing to note here is that there isn’t a tremendous amount of difference between the three different GPUs. I would’ve expected larger differences between a five-year-old 2080 and a 4090. The A100 costs over double to rent.
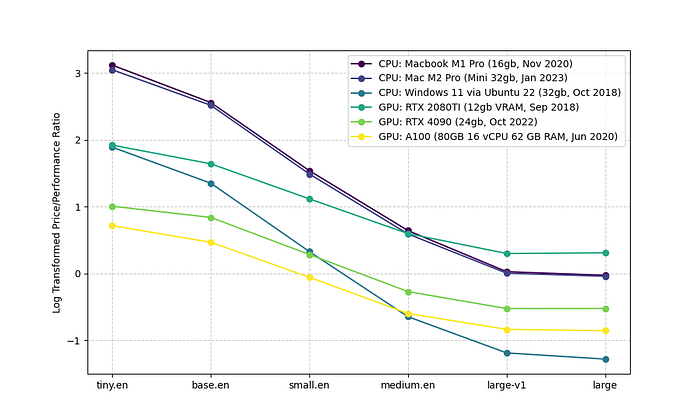
The next visualization shows a log-transformed chart of the price/performance ratio. I haven’t applied any weighting to either the price or the performance, but that can be adjusted in the code. This takes into account the cost, which is essentially the rental cost (which is sometimes $0), and the energy cost. It does not factor in upfront build cost, which would throw off these numbers tremendously. This is only useful if you already have systems lying around or plan to do large workloads, but you can modify the visualization code as needed.
The interesting visuals on these charts are where the lines cross over, suggesting when something may become more valuable. The thing that caught my eye here is that for me personally, if I want to use the medium model, I’m probably better off using my 2080ti. If I were to account for upfront costs, the 4090 and A100 would leap up. Perhaps this code could be adjusted to measure how much time you need to transcribe and use that to weigh up the difference. I’m not sure how representative this chart is, but the weighted log code is valuable if you tweak it to your respective weights.
Whisper Benchmark Viz
I created whisper_benchmark_viz for the benchmark visualizations used to compare the execution time and cost using line charts. It loads data from a JSON file, processes it to calculate average times and price/performance ratios, and plots the results using the matplotlib library. You can modify the data.json.
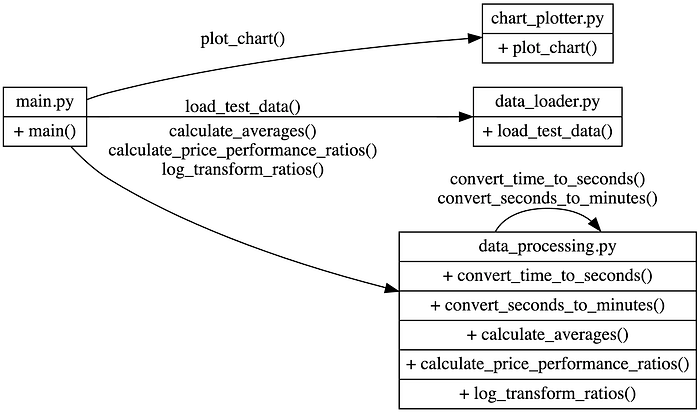
The project is divided into four modules: chart_plotter.py, data_loader.py, data_processing.py, and main.py.
chart_plotter.py
This module defines the plot_chart function that takes the processed data, computer names, test names, and other optional parameters to create a line chart using the matplotlib library. The function sets up the chart properties, such as colors, labels, and gridlines, and plots the data points with markers. Finally, it displays the chart using ply.show().
data_loader.py
This module contains the load_test_data function, which reads a JSON file and returns the test data and related information as a tuple. The function opens the file, loads the JSON data, and extracts the relevant information, such as computer names, power usage, rental costs, and test names.
data_processing.py
This module provides several data processing functions:
1. convert_time_to_seconds: Converts a time string in the excel time format “[h]:mm:ss.000” to seconds.
2. convert_seconds_to_minutes: Converts seconds to minutes.
3. calculate_averages: Calculates the average times for the provided data.
4. calculate_price_performance_ratios: Computes the price/performance ratios for the data using a PricePerformanceArgs dataclass.
5. log_transform_ratios: Log-transforms the provided ratios to normalize the data.
main.py
This is the main script that ties everything together. It starts by loading the data from the JSON file using the load_test_data function. Next, it calculates the averages using the calculate_averages function and plots the average times in a line chart using the plot_chart function.
After that, it calculates the price/performance ratios using the calculate_price_performance_ratios and log-transforms them using the log_transform_ratios function. Finally, it plots the log-transformed ratios in another line chart using the plot_chart function.
pyproject.toml
This file contains the project metadata and dependencies, notably pandas, matplotlib, and numpy. It also specifies the build system using poetry-core.
data.json
This JSON file contains the benchmarking data, including test times, computer names, power usage, rental costs, and test names. The data is organized in a nested list structure, with each inner list representing a computer’s test data.
Alternatively, click here to download the Excel prototype (I switched to matplotlib because I found it more elegant/powerful, but this is useful for anyone who isn’t interested in Python code).
Alternatives
One solid solution is to use OpenAI’s hosted version of the speech-to-text model, priced at $0.006 per minute. It takes a lot of hassle out of the process, and the whole thing can be done with a curl command. Another option is to look at other transcription services, for example, Deepgram, which claims to have a lower word error rate (WER), competitive pricing, and offers diarization (separate per speaker). This is a really important feature for some applications. Visit this link to see how OpenAI compares to Whisper.
On the cloud front, I used runpod because I like their interface, but you should consider vast.ai and lambda labs. Google Colab is another option.

April 20th 2023 Update: Whisper JAX
New TPU based solution that claims 70x speed improvement, v.promising but too new, no benchmarks yet. https://github.com/sanchit-gandhi/whisper-jax
Conclusion
We compared computer models for video transcription. We looked at their cost and speed. Some computers are expensive but not part of the test. We used $0.1331 per kWh for power costs. Cloud computers had rental costs too.
The M1 Pro and M2 Pro Mini offer the lowest cost for running machine learning models for transcribing videos, but there are significant upfront costs depending on your build — while the cloud-based RTX 4090 and A100 provide better performance at a higher cost due to rental fees. Note, the A100 has low availability and can cost over twice as much (to be honest, I would never choose it over the cheaper 4090 instances).
The choice of architecture depends on the desired balance between cost and performance, but I was surprised to find that running my local 2080TI offered great performance, especially with larger models, despite being 5+ years old. It makes sense for my case if I need to use the medium model.
- For people with a budget, the M1 Pro and M2 Pro Mini save energy and money, but they’re still pricey at first. These are ideal dev environments and use remarkably low power for good performance transcribing shorter videos using the smaller models.
- For people who want speed, the RTX 4090 and A100 are better. They’re fast but a lot more expensive. If you don’t have decent on-premise systems, this may still be your best choice… just develop on the cloud with a web browser. Note, I probably wouldn’t opt for the A100 as it’s not that much faster than the 4090.
- The RTX 2080 Ti is old but offered really competitive performance and became much more viable when you get into larger videos using the >small transcription models. For a mix of cost and speed, a local RTX 2080 Ti is a good option. It’s good for people who want both things, but has the highest power draw (297 watts)
- Think about your needs. How often will you transcribe videos? How fast do you want it done? What’s your budget? This helps you choose the right computer.
- Watch for new technology. Better, cheaper options might come soon. Be ready to change your choice if needed.
- Consider just offloading the whole job to the API service or Deepgram.
In short, your choice depends on your needs and budget. Think about the cost and speed of each option. Then pick the best one for you.
Good luck, and thanks for reading!
Resources
Repositories referenced in this article:
YouTube to Whisper GitHub — C++
YouTube to Whisper — GPU
Whisper Benchmark GitHub
whisper by OpenAI (native pytorch repository, GPU)
whisper.cpp by Georgi Gerganov
GeForce RTX 20 Series Graphics Cards and Laptops | NVIDIA
GeForce RTX 4090 Graphics Cards for Gaming | NVIDIA
Matplotlib — Visualization with Python
Rent Cloud GPUs from $0.2/hour (runpod.io)
GPU Cloud, Workstations, Servers, Laptops for Deep Learning | Lambda (lambdalabs.com)
Welcome To Colaboratory — Colaboratory (google.com)
Deepgram — Automated Speech Recognition
Introducing M1 Pro and M1 Max: the most powerful chips Apple has ever built — Apple

